The single fact that you clicked on that link to come here shows that you are brave. Most people just run away when it comes to regular expressions. They are wrong to do so! Not only are they extremely valuable, but their foundations also are actually quite easy to grasp.

However, regular expressions are hard to read, if not to say barely decipherable. That’s why I thought an article on the basics of regular expressions would not be such a bad idea after all. And to avoid the very theoretical approach, I feel like actually building a regular expression the hard way from the ground up would be a good way to learn.
Disclaimer! I am not an expert in regular expressions, although I guess I can make my way in most situations with them, as long as it’s not getting overly complex. If you happen to find a way to improve this code, be kind enough to explain what you would do in the comments. That would be super great. :)
What is this all about?
In case you are not entirely sure what this is all about, allow me to put you back on track. A regular expression, often shortened as “regex” or “regexp”, is a sequence of characters that define a search pattern. Because of their usefulness, regular expressions are built-in in most programming languages. A very practical example would be a regular expression to validate an email address.
That being said it is important to point out that not all regular expression engines are the same. You might have heard of PCRE (Perl Compatible Regular Expression) or POSIX regular expressions. PCRE is the engine used in many languages including PHP, and can be thought as regex on steroids. It is the “new standard” so to say. However not all languages stick to PCRE. For instance JavaScript has a limited support of PCRE and a lot of features, such as the ability to write regular expressions on several lines using safe spaces and line-breaks, are absent.
Also, as it is forbidden to write about regular expressions without dropping some bombs, here is a famous quote to get started:
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems. — Jamie Zawinski
Note: to play with regular expressions, I highly recommend Regexr which not only is extremely well thought, but also provides a handy reference as well as a way to save a regular expression for sharing. There is also Regex101 which is a great tool to fiddle with regular expressions.
Finding a use-case
Everything started from a tweet from Greg Whitworth about regular expressions:
This is my most illegible regex to date:
\w+\[\w+(\|\=|\*\=|\$\=|\^\=|~\=|\=)(|\")\w+(|\")](|\s+){
It does look illegible. As most regular expressions. I started discussing with Greg about what he was trying to achieve and learnt he wanted to find CSS attribute selectors in a document. It seemed like a fun challenge so I spent a few minutes on it and came up with this:
\[[a-z][a-z0-9-]*([|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(\s+i)?)?]In this article, we will see how to come up with such a monster, and what are the required steps to get there. But first, let’s be clear on what we want to match: attribute selectors. These are some examples of selectors we want to match:
- No value:
[foo] - Empty value:
[foo=""] - Unquoted valid value:
[foo=bar] - Quoted value using double quotes:
[foo="bar baz"] - Quoted value using simple quotes:
[foo='bar baz'] - Modulators:
[foo^='bar'],[foo$='bar'],[foo|='bar'],[foo~='bar'],[foo*='bar'] - Case-sensitivity flag with unquoted valid value:
[foo=bar i] - Case-sensitivity flag with quoted value using double quotes:
[foo="bar" i] - Case-sensitivity flag with quoted value using simple quotes:
[foo='bar' i]
On the other hand, these are some examples of things we do not want to match:
- Invalid modulator:
[foo@='bar'] - Unquoted invalid value:
[foo=bar baz] - Non-matching quotes:
[foo='bar"],[foo="bar'] - Non-closed quotes:
[foo='],[foo="] - Non-closed brackets:
[foo - Invalid flag:
[foo='bar' j]
We will also assume that selectors are correctly written, sticking to what is possible and allowed by the specifications. For instance, the following are theoretically invalid:
- Attribute name starting with number:
[42foo] - Attribute name containing undescores:
[foo_bar] - Attribute name containing uppercase characters:
[FOO] - Attribute name containing invalid characters:
[-\_(ツ)_/¯]
Alright? Let’s get started slowly but surely.
Note: for sake of readability, I omitted the PCRE delimiters (/…/) from all regular expressions in this article. We also won’t talk about flags as they are basically irrelevant to this discussion.
Matching a raw attribute selector
Let’s start easy. We want to match an attribute selector that only checks for the presence of the attribute, without checking its value, such as [href]. To do so, we are looking for a word inside of brackets.
To match a word character, we can use the \w meta character. This literally means:
Matches any word character (alphanumeric & underscore). Only matches low-ascii characters (no accented or non-roman characters). Equivalent to
[A-Za-z0-9_].
So the very first version of our regular expression to match an attribute selector would look like this:
\[\w+]Let’s dissect it:
\[: matches an opening square bracket. The leading backslash is a way to escape the next characted. It is needed as[has a special meaning in regex.\w: matches a word characted which is basically a lowercase letter, an uppercase letter, a number or an undescore.+: matches the last token (here\w) at least one time. Here, we want to imply that we need at least one character.]: matches a closing square bracket. As there is no unescaped opening bracket, this one does not need to be escaped.
So far so good, right? Let’s check our test list to see how our regular expression performs.
![\[\w+]](/assets/images/learning-regular-expressions/01.png)
Oops, \w+ is actually not quite right! For starters, we do not want the attribute name to start with a number, and we don’t want to allow underscores either, only hyphens. Along the same lines, uppercase letters are not actually allowed, so instead of \w+ we should check for: [a-z][a-z0-9-]*. This means a mandatory latin letter that can be (but not necessarily) followed by any number of latin letters, numbers or hyphens. This is what the star (*) implies: from 0 to infinity. Our regex is now:
\[[a-z][a-z0-9-]*]![\[[a-z][a-z0-9-]*]](/assets/images/learning-regular-expressions/02.png)
To be completely honest, we could actually very slightly tweak our regular expression and stop here. Think about it: what if we said that an attribute selector is an opening bracket followed by anything, and then a closing bracket? As a regular expression, that would look like this:
\[[^\]]+]This bracket mess literally means “find an opening square bracket, followed by anything that is not a closing square bracket, followed by a closing square bracket”. To do so, it relies on a negated set that we will see more in-depth in the next section.
Broadly speaking, it is more than enough to find attribute selectors in a stylesheet but we didn’t learn much! Also, this version captures a lot of poorly formatted selectors, as well as some false-positive results as you can see in the next image. Let’s try to match a valid selector!
![\[[^\]]+]](/assets/images/learning-regular-expressions/03.png)
Matching attribute selectors with values
We now want to match raw attribute selectors as well as attribute selectors checking for the value. For now, let’s focus on something like [foo=bar] without caring too much about modulators and quotes. Let’s put our current version here:
\[[a-z][a-z0-9-]*]To match a value, we need to check for the presence of an equal sign (=), then a series of at least one character that is not a closing square bracket (for now). To match anything that is not a specific character we use a negated set, written as: [^X] where X is the character you do not want to match (escaped if needed).
A negated set is a way to match any character that is not in the set.
So to match anything that is not a closing square bracket, it is: [^\]], as we’ve seen in the previous section. Our regex is now:
\[[a-z][a-z0-9-]*=[^\]]+]![\[[a-z][a-z0-9-]*=[^\]]+]](/assets/images/learning-regular-expressions/04.png)
Oh-ho though… Now [foo] doesn’t match anymore! That’s because we did not make the equal + something part optional. We can do that by wrapping it in parentheses and add a question mark right after it ((..)?). Like so:
\[[a-z][a-z0-9-]*(=[^\]]+)?]The question mark says:
Matches 0 or 1 of the preceding token, effectively making it optional.
![\[[a-z][a-z0-9-]*(=[^\]]+)?]](/assets/images/learning-regular-expressions/05.png)
That’s going somewhere! Attribute selectors can involve a modulator before the equal sign to add extra validations. There can be only 0 or 1 modulator at a time, and it has to be one of: |, *, $, ^, ~. We can make sure the modulator is valid by using a character set. To make it optional, there again we will use the question mark:
\[[a-z][a-z0-9-]*([|*$^~]?=[^\]]+)?]![\[[a-z][a-z0-9-]*([|*$^~]?=[^\]]+)?]](/assets/images/learning-regular-expressions/06.png)
Dealing with quotes
Like many languages, CSS does not enforce a specific quote style. It can be either double (") or simple ('). Actually most of the time, quotes can be safely omitted! It is the case for attribute values, as long as they don’t contain any specific character. It is best practice to put them anyway, but our regular expression should make sure it works for valid unquoted values as well.
So instead of matching anything but a closing square bracket, we want to match either:
- a double quote (
") followed by anything that is not a double quote or a forbidden line break (using the\ncharacter class), then a double quote again:"[^"\n]*". - or a single quote (
') followed by anything that is not a single quote or a line break, then a single quote again:'[^'\n]*'. - or anything (yet at least 1 character) that is not a double quote, a single quote, a space-like character (using the
\scharacter class) or a closing square bracket:[^"'\s\]]+.
To achieve this, we can use the alternation operator |:
Acts like a boolean OR. Matches the expression before or after the
|. It can operate within a group, or on a whole expression. The patterns will be tested in order.
It gives us this pattern:
("[^"\n]*"|'[^'\n]*'|[^"'\s]+)Which we can now incorporate in our expression:
\[[a-z][a-z0-9-]*([|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+))?]![\[[a-z][a-z0-9-]*([|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+))?]](/assets/images/learning-regular-expressions/07.png)
Testing the case-insensitive flag
CSS Selectors Level 4 introduces a flag to attribute selectors to discard case-sensitivity. When present, this option tells the browser to match no matter whether the case is matching the requested one.
This flag (noted i) must be present after at least 1 space right before the closing square bracket. Testing for it in our regular expression is actually super easy using \s+i.
\[[a-z][a-z0-9-]*([|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(\s+i)?)?]![\[[a-z][a-z0-9-]*([|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(\s+i)?)?]](/assets/images/learning-regular-expressions/08.png)
Capturing sections of content
Regular expressions are not exclusively made for matching and validating content. They are also super useful when it comes to capturing some dynamic content as part of a search pattern. For instance, let’s say we want to grab the attribute value in our regular expression.
Capturing content as part of a regular expression is made with parentheses ((..)). This is called a capturing group:
Groups multiple tokens together and creates a capture group for extracting a substring or using a backreference.
You might be confused as we already used parentheses in our expression but not for capturing. We used them to group tokens together. This kind of behaviour is what makes the language of regular expressions difficult to grasp: it is not regular, and some characters have different meanings depending on their position or the context they are used in.
To use parentheses as a grouping feature without capturing anything, it is needed to start their content with a question mark (?) directly followed by a colon (:), like this: (?: … ). This intimates the engine not to capture what is being matched inside the parentheses. We should update our expression to avoid capturing the equal part (as well as the case-sentivity flag):
\[[a-z][a-z0-9-]*(?:[|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(?:\s+i)?)?]As you can see, we added ?: right after the first opening parenthese so we do not capture what is being matched. On the other hand, the second opening parenthese, after the equal sign, is capturing the attribute value. Which could be desired! Now, if we want to capture the attribute name as well, we only have to wrap the relevant part of the regex in parentheses:
\[([a-z][a-z0-9-]*)(?:[|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(?:\s+i)?)?]To make it easier to understand, consider this selector: [href^="#"]. When running the previous regular expression against it, we will capture 2 things:
href: the attribute name"#": the attribute value
![\[([a-z][a-z0-9-]*)(?:[|*$^~]?=("[^"\n]*"|'[^'\n]*'|[^"'\s\]]+)(?:\s+i)?)?]](/assets/images/learning-regular-expressions/09.png)
If we want to grab the value only, without the possible quotes, we need to move the capturing group inside the quotes. Depending on the purpose of the regular expression (validation, capture, etc.), it might be interesting or even needed to use capturing groups to grab content from the matched patterns.
Final words
That’s it! The final state of our regular expression is able to correctly match and validate a CSS attribute selector. I have run some tests on it and could not find a reasonable way to break it (as long as the selectors are sticking to what is allowed by the CSS specifications).
As you can see, it is not that hard to write a decent regular expression, especially when you take it slow and build it step by step. Do not try to rush the perfect solution right away. Start with the basic match, then enhance it to deal with more complex scenarios and edge cases.
It is worth noting that the difficulty with regular expressions is usually not to write them but to read them, and thus maintain them. Therefore, it is highly recommended to extensively unit-test code snippets relying on regular expressions. It can be a huge time-saviour when updating a regular expression to have a few dozens of tests making sure that the behaviour didn’t break.

Last but not least, Adonis mentioned in the comments a very handy tool to visualize the meaning of a regular expression in a graphical way. This tool, called Regexper manages to define an render a graph based on a given regular expression. Impressive! Here is the graph for our regex (using non-capturing groups only for the sake of simplicity):
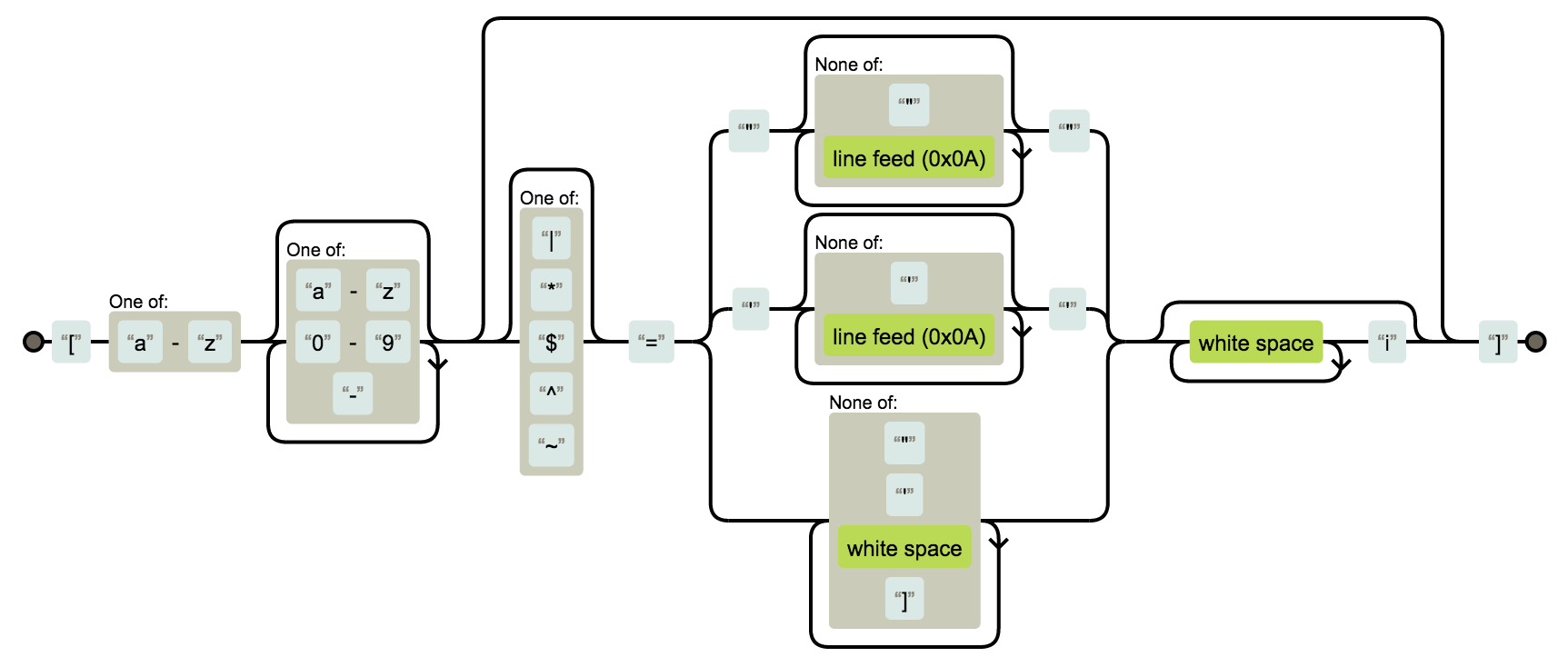
I hope you learnt a few things anyway. And if you find a way to improve it, be sure to share in the comments!
Huge thanks to my brother Loïc for helping me making this article a valuable piece of information about regular expressions. :)